Back story…
tl;dr - some monitoring back story and not being dogmatic about your beliefs.
UPDATE: I am writing a book about Prometheus take a look.
As many folks know, I am one of the maintainers of Riemann, an event stream processor focussed on monitoring distributed systems. I wrote a book about monitoring in which I used Riemann as a centerpiece to explore new monitoring patterns and approaches. In the book, I describe an architecture of whitebox monitoring (with some selective blackbox monitoring) using a push-based model.
What do I mean by that? Let’s define some concepts. Blackbox monitoring probes the outside of a service or application. You query the external characteristics of a service: does it respond to a poll on an open port and return the correct data or response code. An example of blackbox monitoring is performing an ICMP check and confirming you have received a response.
Whitebox monitoring instead focuses on what’s inside the service or application. The application is instrumented and returns its state, the state of internal components, or the performance of transactions or events. This is data that shows exactly how your application is functioning, rather than just its availability or the behavior of its surface area. Whitebox monitoring either emit events, logs and metrics to a monitoring tool or exposes this information on a status or health endpoint of some kind, which can then be scraped by a monitoring tool.
Most folks doing modern monitoring acknowledge that whitebox monitoring should represent your largest investment. The information exposed from an application’s internals is far more likely to be of business and operational value than what is exposed on the surface. That’s not to say blackbox monitoring is a total waste. The external monitoring of services and applications is useful, especially for services that are outside of your control, or when the external view provides some context you might not see internally, like a routing or DNS issue.
In the book I also focus on push-based monitoring over pull-based monitoring. Many (most?) monitoring systems are pull/polling-based systems.1 With a pull-based model, your monitoring system queries or scrapes the service or application being monitored. With a push-based architecture, your services and applications are emitters, sending data to your monitoring system.
There are lots of reasons I favor the push model versus the pull model but for many folks the distinction is arbitrary.2 Indeed, many of the concerns of either approach don’t affect implementation due to issues like scale. And other concerns, like many arguments over implementation or tool choice, don’t change the potential success of the implementation.3 I’m a strong exponent of using tools that work for you, rather than ill considered adoption of the latest trend or dogmatism.
It’s this lack of distinction for folks, and a desire not to be dogmatic about my beliefs, that has encouraged me to write an introductory walk-through of one of the leading pull-based monitoring tools: Prometheus. Prometheus has some excellent current buzz, especially in the Kubernetes and container world. Let’s take a look at it.
Introducing Prometheus
Prometheus owes its inspiration to Google’s Borgmon and was developed by some ex-Google SRE’s at Soundcloud. It’s written in Go, open source, and is incubated under the Cloud Native Computing Foundation.
Prometheus focuses on the whitebox monitoring of applications and services. Prometheus works by scraping time series data exposed from applications and services. The time series data is exposed by an application itself or via plugins called exporters as HTTP endpoints.4
The Prometheus platform is centered around a server which does the pulling and storage of time series data. It has a multi-dimensional time series data model which combines metric names and key/value pairs called labels for metadata. Time series are stored in the server, single servers are autonomous, and don’t rely on distributed storage.5
The platform also includes client libraries and a series of exporters for specific functions and components, for example a StatsD exporter that can receive StatsD-formatted time series data and expose it as Prometheus time series data. There is a push gateway for accepting small volumes of incoming time series data. Lastly, there’s an alert manager, which can handle alerts generated from thresholds or triggers on time series data collected by Prometheus.

A more fancy architecture is in the Prometheus documentation.
In this walk through, I’m going to install Prometheus and then use it to monitor some resources.
Installation
The Prometheus server is a single binary, aptly titled prometheus. Let’s grab the latest version of the binary and unpack it.
$ wget https://github.com/prometheus/prometheus/releases/download/v2.2.1/prometheus-2.2.1.darwin-amd64.tar.gz$ tar -xzf prometheus-*.tar.gz$ cd prometheus-2.2.1.darwin-amd64/The download site also has some stand-alone add-ons: the alert manager for alert management and the various exporters for exporting monitoring information.
Configuration
The prometheus binary we’ve just unpacked is configured via a YAML file. Prometheus ships with a default file: prometheus.yml. Let’s take a peek at that file:
global: scrape_interval: 15s evaluation_interval: 15s
rule_files: # - "first.rules" # - "second.rules"
scrape_configs: - job_name: 'prometheus' static_configs: - targets: ['localhost:9090']Our default configuration file has three YAML blocks defined.
Global
The first block global contains global settings for controlling the server’s behavior.
The scrape_interval specifies the interval between scrapes of any application or service, in our case 15 seconds. This will be the resolution of your time series data, the period in time that each datapoint in the series covers.
The evaluation_interval tells Prometheus how often to evaluate its rules. Rules come in two major flavors: recording rules and alerting rules. Recording rules allow you to precompute frequent and expensive expressions and save their result as a new set of time series data. Alerting rules allow you to define alert conditions. Prometheus will (re-)evaluate these rules every 15 seconds.
Rule files
The second block, rule_files, specifies a list of files that can contain the recording or alerting rules.
Scrape configuration
The last block, scrape_configs, specifies all of the targets that Prometheus will scrape. Prometheus calls targets instances and groups of instances are called jobs. Our default configuration has one job defined called prometheus. Inside the job we have a static_config block, which lists the instances. The default prometheus job has one instance: the Prometheus server itself. It scrapes the localhost on port 9090 which returns the server’s own health metrics. Prometheus assumes that metrics will be returned on the path /metrics, so locally it scrapes the address localhost:9090/metrics. You can override the path using the metrics_path option.
The single job is a bit dull though, let’s add another job, this one to scrape our local Docker daemon. We’ll use the instructions in the Docker documentation to configure the Docker daemon to enable metrics on localhost:9323/metrics. We can then add a new job called docker.
- job_name: 'docker' static_configs: - targets: ['localhost:9323']Our job has a name and an instance, that references our local Docker daemon’s metrics endpoint. The path assumes the default of /metrics.
You can find the full configuration of this Prometheus server as a gist.
Starting the server
Let’s start the server and see what happens.
$ ./prometheus --config.file "prometheus.yml"We run the binary and specify our configuration file in the --config.file command line flag. Our Prometheus server is now running and scraping the instances of the prometheus and docker jobs and returning the results.

Dashboard
Prometheus comes with a built-in interface where we can see these results. Point your browser at http://localhost:9090/graph to see it.
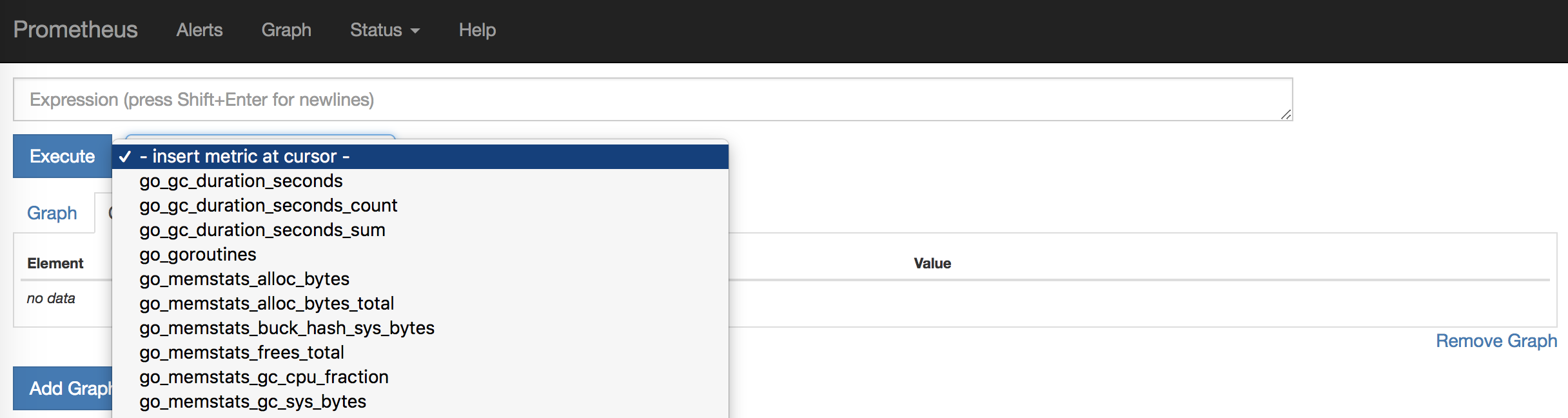
You should be able to click on the - insert metric at cursor - to select one of the metrics Prometheus is collecting from itself. Let’s look at its HTTP requests. Select the http_requests_total metric and click Execute.
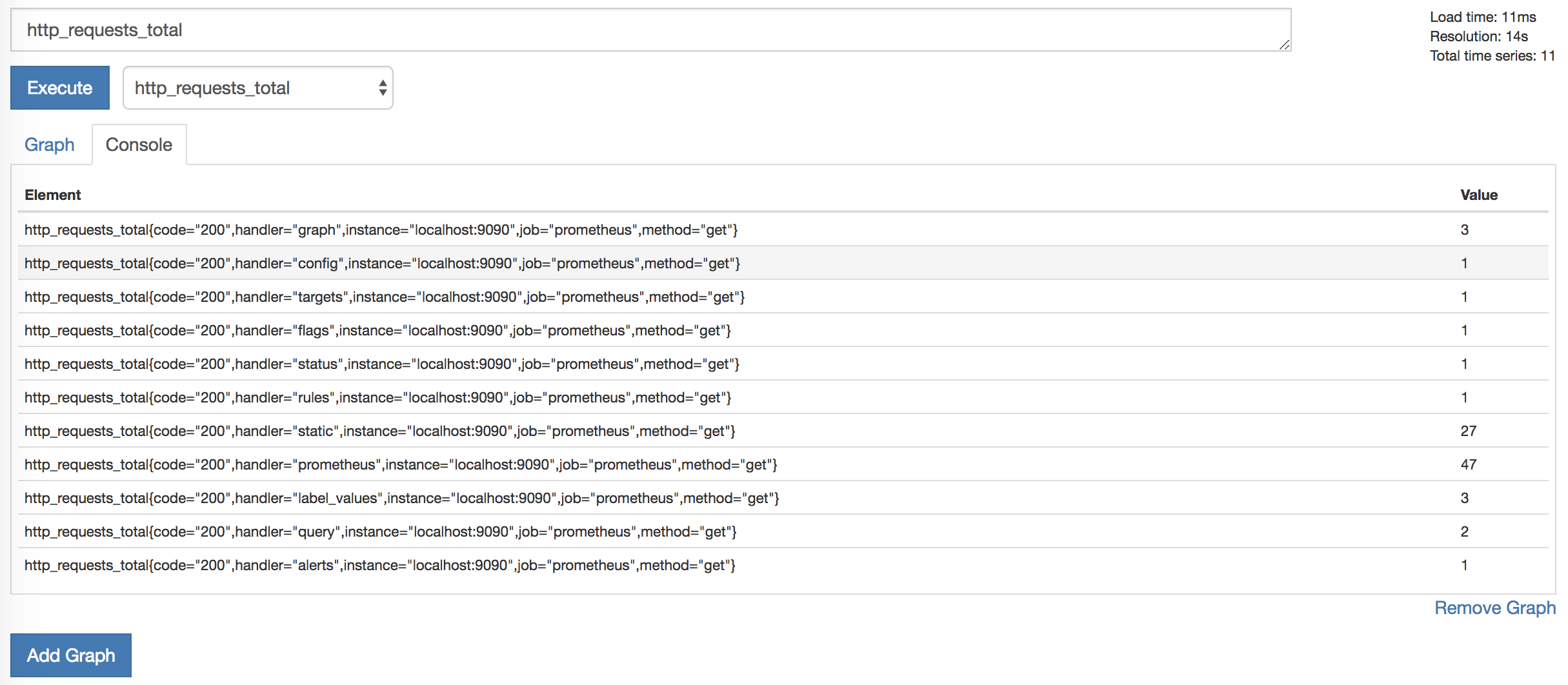
You’ll see a list of elements and values, for example:
http_requests_total{code="200",handler="prometheus",instance="localhost:9090",job="prometheus",method="get"}These elements are metrics split by additional dimensions. The dimensions are provided by labels on the metrics. For example, the http_requests_total metric has a label of handler, containing the specific handler which generated the request. We can narrow this list of metrics down by querying for a specific metric using one of those labels. Prometheus has a highly flexible expression language built into the server, allowing you to querying and aggregate metrics.

Here we’ve used the handlers label to select only that metric for the prometheus handler. Querying labels is especially nice when you’re used to parsing dotted string named metrics.
We can also aggregate our HTTP request metrics. Let’s say we wanted to see the total per job per-second rate for HTTP requests over the last five minutes. To do this we specify a query like so:
sum(rate(http_requests_total[5m])) by (job)
This combines the sum function of a rate for the http_requests_total over 5m and broken out by job. We then Execute the query.

We can then easily graph the results by clicking the Graph tab.

This shows the total HTTP request rate, grouped by job, for the last five minutes.
We can also save these queries as recording rules and ensure they are calculated automatically and a new metric created from the rule. To make this expression a rule, we’d add a file to our rule_files block.
rule_files: - "first.rules" # - "second.rules"And put the following rule in the first.rules file:
job:http_requests_total:sum = sum(rate(http_requests_total[5m])) by (job)
This will create a new metric, job:http_requests_total:sum, for each job.

You could then graph the metric and add it to a dashboard.
Alerting
Alerting, like aggregation, is rule-based. To add an alerting rule we would add another file to our rule_files block.
rule_files: - "first.rules" - "second.rules"Let’s create a new rule in the second.rules file that will alert when instances are down. To do this we can use one of the default metrics for a scrape: up. (Other default metrics include the duration and volume of metrics.) The up metric is a heartbeat. Its value is set to 1 when a scrape is successful or to 0 if the scrape fails.
To do this we add an alert rule to our rules file that looks like this:
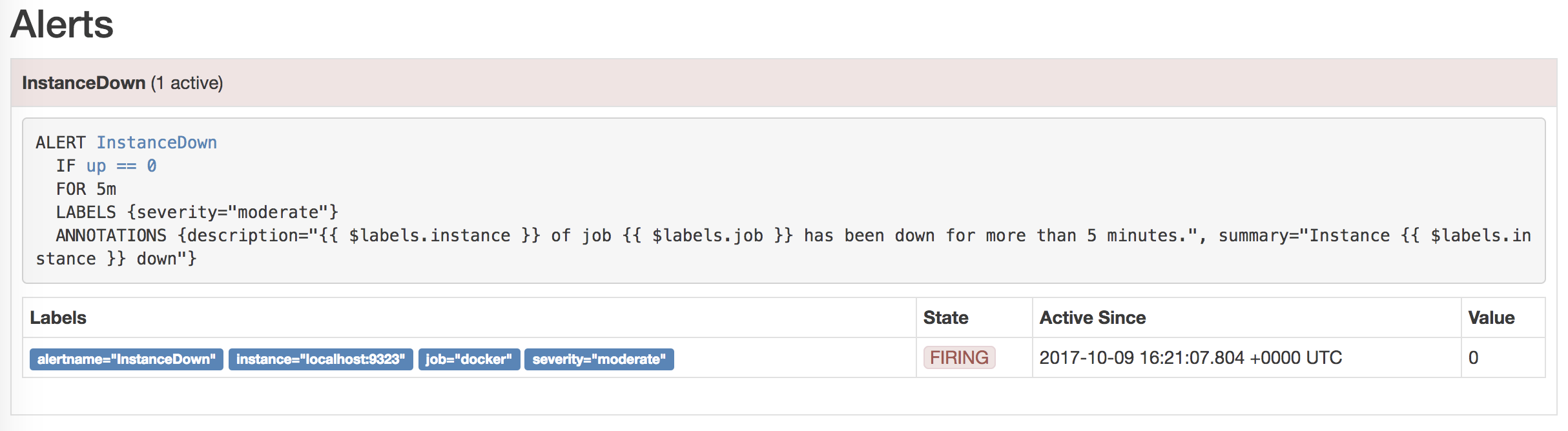
ALERT InstanceDown IF up == 0 FOR 5m LABELS { severity = "moderate" } ANNOTATIONS { summary = "Instance {{ $labels.instance }} down", description = "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes.", }An alert rule looks a little like a conditional query. We give it a name, here InstanceDown, and a set of conditions. Our InstanceDown alert triggers when the up metric is 0 (i.e. a scrape failed) for five minutes. We’ve added a label to the alert, a severity of moderate, and some annotations. Annotations allow you to attach longer information to an alert, a description for example. Inside the annotations, you can see the use of {{ }}, Go templating braces, containing variables. This allows us to customize alerts using templating. Here the $labels variable contains the metric’s labels, for example the $labels.instance returns the instance name, $labels.job the job name, etc.
Now, if we were to stop our Docker daemon, after five minutes Prometheus would trigger our alert. Prometheus sends alerts to a configurable alert manager destination. It comes with a pre-built manager called Alertmanager, that you’ll need to install and run separately, or you can specify your own, for example it integrates well with The Guardian’s Alerta tool.
You can see your current Alerts in the dashboard on the Alerts tab.
Final thoughts
Prometheus is a neat platform. It’s readily installable, its configuration is clear, and being YAML is amenable to configuration management.6 The autonomous server makes architecture relatively painless for simple environments. I’m curious about patterns for more complex environments, especially redundant and highly available monitoring (and alerting). I couldn’t find a lot of examples and I’m interested in experimenting with some approaches to see what’s feasible.
The flexibility of the data model, especially the ease with which you can add and query labels on metrics, is nice. I also played with most of the client libraries and several of the exporters and found them pretty straightforward. Creation of instrumentation and generation of metrics wasn’t overly complex.
The inbuilt interface is clean and elegant and, combined with the query language, feels like the sort of tool I like a great deal when debugging or capacity planning. The recording rules also seem like a good underlying approach for aggregating metrics.
I only lightly explored storage, security, service discovery, federation, or much of the available integrations but the capabilities look reasonably comprehensive. A quick scan of GitHub also revealed a solid collection of tools, integrations and examples to get folks started.
The main platform has pretty solid documentation but some of the adjacent projects are a little disjointed or lacking in documentation. However, from having limited knowledge of Prometheus, it took me a matter of an hour or so to have some fairly solid basic configuration in place.7
It’s perhaps not a turnkey deployment, shipping a single binary without packaging or init scripts, but that’s becoming less of a concern for a lot of projects.8 There’s also some prior deployment art in configuration management code, that could be used. Indeed, most folks exploring something like Prometheus would potentially be able to bootstrap all of that themselves.
Its strong support of containers and Kubernetes is very attractive for folks using those tools. The autonomous and portable nature of the server is also attractive for those exploring (micro-)services, dynamic, or Cloud-based stacks.
Overall, if I was looking at a new monitoring implementation project, I’d strongly consider Prometheus. It’s also well worth investing some time in if you’re moving towards containers and tools like Docker and Kubernetes. It’s likely to be more flexible and better suited to those tools and architectures than many existing platforms.
P.S. This post owes inspiration from reading Cindy Sridharan’s post Monitoring in the time of Cloud Native. That greatly encouraged me to do some monitoring writing. Thanks Cindy!
Footnotes
-
An excellent example is Nagios. ↩
-
Scalability, discoverability, security… I talk more about it in the book. Anyways, buy me a ginger ale at a conference and we can argue about it. Moving on… ↩
-
Let me talk to you sometime about model-based configuration management… :) ↩
-
There’s also a push gateway to which you can send time series data. ↩
-
Although you can send events on to some form of distributed storage or federate multiple Prometheus servers. ↩
-
And you should be looking at configuration management. ↩
-
In fairness though, I do a lot of monitoring work so might be a poor example. ↩
-
Ding dong, the operating system is dead, etc. ↩